This is an old revision of the document!
Object pose representation
Information about the poses and dimensions of objects is crucial for finding and manipulating them. In KnowRob, object dimensions are described as simple bounding boxes or cylinders (specifying the height, and either width and depth or the radius). While this is clearly not sufficient for grasping, we chose this description as a compromise in order not to put too many details like point clouds or meshes into the knowledge base. Such information is rather linked and stored in specialized file formats.
Object poses are described via homography matrices. Per default, the system assumes all poses to be in the same global coordinate system. Pose matrices can, however, be qualified with a coordinate frame identifier. The robot can then transform these local poses into the global coordinate system, for example using the tf library.
Since robots act in dynamic environments, they need to be able to represent both the current world state and past beliefs. A naive approach for describing the pose of an object would be to add a property location that links the object instance to a point in space or, more general, a homography pose matrix. However, this approach is limited to describing the current state of the world – one can express neither changes in the object locations over time nor differences between the perceived and an intended world state. This is a strong limitation: Robots would not be able to describe past and (predicted) future states, nor could they reason about the effects of actions.
Memory, prediction, and planning, however, are central components of intelligent systems. The reason why the naive approach does not support such qualified statements is the limitation of OWL to binary relations that link exactly two entities. These relations can only express if something is related or not, but cannot qualify these statements by saying that a relation held an hour ago, or is supposed to hold with a certain probability. For this purpose, we need an additional instance in between that links e.g. the object, the location, the time, and the probability.
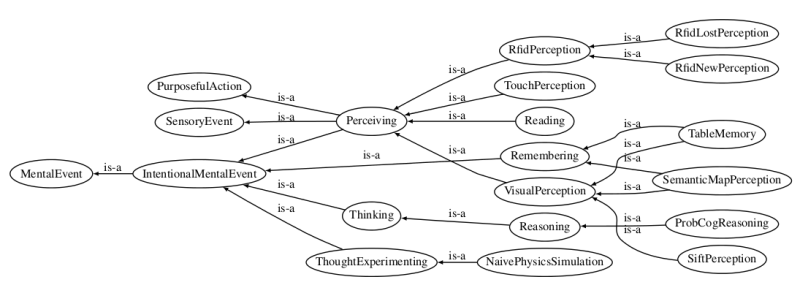
In KnowRob, these elements are linked by the event that created the respective belief: the perception of an object, an inference process, or the prediction of future states based on projec- tion or simulation. The relation is thus reified, that is, transformed into a first-class object. These reified perceptions or inference results are described as instances of subclasses of MentalEvent (Figure 3.4), for instance VisualPerception or Reasoning. Object recognition algorithms, for in- stance, are described as sub-classes in the VisualPerception tree. Multiple events can be assigned to one object, describing different detections over time or differences between the current world state and the state to be achieved (Figure 3.5).
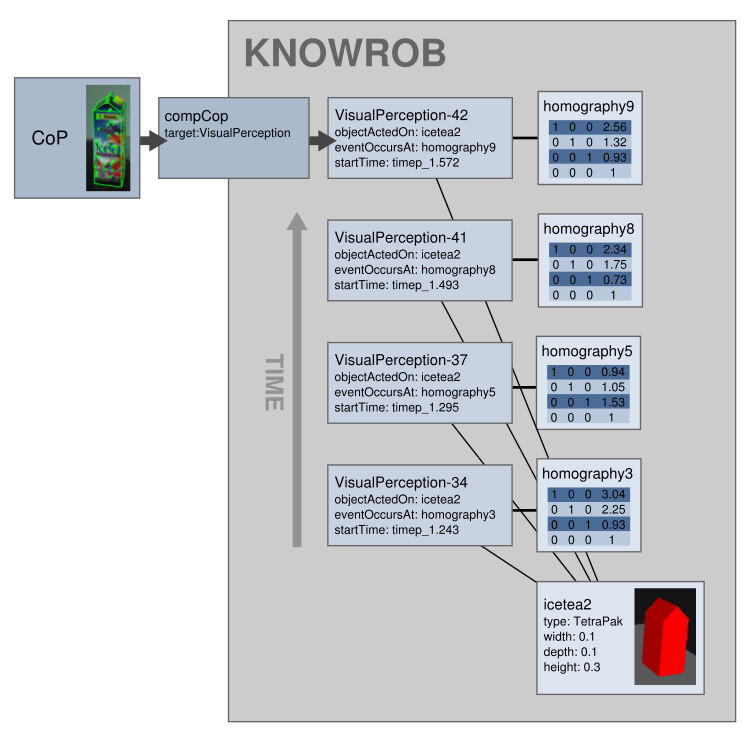
This representation is similar to the fluent calculus [Thielscher, 1998], in which fluents are objects that represent the change of values over time. In our case, however, the reified objects contain more information than just a changing value: the current and all past states of the relation, including the times at which state changes were detected, and the type of event that established the relation. Using our representation, we can describe multiple “possible worlds”, for example the perceived world, a description of how the world is supposed to look like, and the world state a robot predicts as the result of some actions it performs. Since all states are represented in the same system, it becomes possible to compare them, to check for inconsistencies or to derive the required actions, which would be difficult if separate knowledge bases would be used for perceived and inferred world states.
(text taken from Tenorth,2011)
